// Research / Trust, PII & Safety
PII redaction that catches the languages Presidio misses.
Your DPO won't sign off on sending customer names and national IDs to a US LLM API. We sit between your app and the model with multilingual neural detection, reversible tokenization, and audit logs your compliance team can actually query - so the LLM never sees what it doesn't need to.
// What we see
Demo passes English. Production fails on Polish, German, French.
01
Presidio is English-first
The standard stack (Presidio + spaCy) handles English well and degrades quietly on everything else. Polish PESEL, German Steuer-ID, French NIR, Italian codice fiscale go undetected. The compliance team finds out when an auditor pulls a sample.
02
Regex misses the long tail
PESEL has a checksum so regex catches it. Names don't. Internal MRNs, employee IDs, account numbers wrapped in domain prose - those need a model. Teams that stop at regex ship a redactor that catches the easy 60% and leaks the rest.
03
Reversibility is an afterthought
Most teams discover at the end of week one that the LLM needs to see something useful in place of redacted spans, and that the response needs the originals back. Without stable placeholders and a vault, you either lose semantics or leak PII in the rehydration step.
// Case Study
GDPR-compliant PII redaction - 24 EU languages, drop-in
Every GDPR-bound team we worked with was hand-rolling their own preprocessing - regex stacks, per-language NER, hours of pipeline work per dataset, and coverage that stopped at the languages they had labelers for. We shipped `bardsai/eu-pii-anonimization-multilang` as the drop-in library that replaces all of it: one import covers 24 EU languages with a GDPR-aware tagging schema, recall-tuned because false negatives leak. 0.890 F2 on the Gretel benchmark; hours of pipeline work collapse to seconds per dataset.
0.890
F2 on Gretel PII benchmark
24
EU languages with one model
Hours → s
preprocessing per dataset
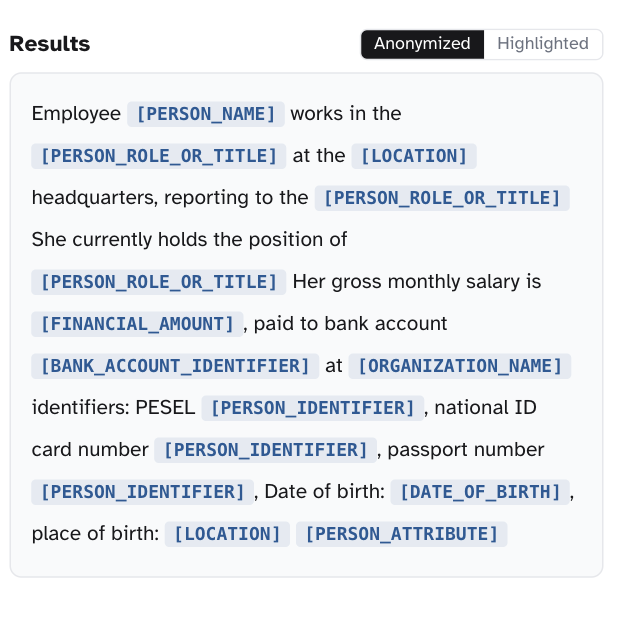
// What we do
Three things that make PII redaction hold up in regulated traffic.
The model that catches non-English entities, the tokenization layer that keeps the LLM useful, and the audit log your DPO can hand to a regulator. The rest is integration.
A model trained on EU languages
bardsai/eu-pii-anonymization-multilang - our published Hugging Face model, trained on 20+ languages including the ones Presidio degrades on. Fine-tunable on your domain (medical, legal, financial) when the public taxonomy doesn't cover your identifiers.
Reversible tokenization with a vault you own
Each entity is replaced with a stable placeholder like [PERSON_1]; the original lives in a vault on your infrastructure. The LLM reasons over placeholders, the response gets rehydrated on the way back. Per-tenant keys, rotation, and an optional one-way mode for stricter policies.
Per-entity F1 measured on your data
Vendor benchmarks aren't your distribution. We measure per-entity, per-language F1 on your held-out set before go-live, and tune confidence thresholds to your risk model - conservative on national IDs, more permissive on locations. The metric reflects what you're actually shipping.
// Method fit
Edge redaction isn't the right control for every privacy problem.
skip it if
Your LLM is already inside your perimeter
If you're running open-weight models on your own hardware and customer data never leaves your network, the egress problem doesn't exist. Redaction inside your perimeter is a different design - usually about minimizing data in logs and traces, not at the model boundary.
On-Prem & Air-Gapped LLMYou only handle English text
Microsoft Presidio plus a tuned spaCy pipeline gets you a long way on English-only traffic. Custom is for the multilingual case, for domain identifiers spaCy doesn't carry, or when reversible tokenization is part of the requirement.
Your problem is structured data exfil
Customer records leaving via SQL exports, API responses, or backup pipelines aren't an LLM problem - they're a data-loss-prevention problem. Different stack (DLP gateways, data classification, egress firewalls), different vendor list.
use it if
Edge PII redaction fits when you call third-party LLM APIs with customer text, operate across multiple languages, need reversible tokenization to keep responses useful, and have a DPO who needs an audit trail rather than a vendor claim.
// How we work
Measure first. Tokenize early. Hand off the audit trail.
Every PII engagement starts with a measurement on your data, not a vendor benchmark. The architecture is decided after we know which entities your traffic actually contains and at what rate.
01
Measure on your traffic (week one)
We run the base model on a sampled, redacted-for-handling slice of your traffic and report per-entity, per-language F1. The number you ship against is calibrated to your distribution before any integration code is written.
02
Integrate where the trust boundary is
Proxy, SDK, or sidecar - we pick by where your trust boundary sits, not by what's easiest to demo. Streaming-aware: PII tokens get redacted before they leave the boundary, not after the response is done.
03
Hand off the audit trail
We hand off the model, the vault schema, the integration code, and an audit-log dashboard your compliance team can query for Article 30 records. Slack for 30 days after delivery for the questions that come up after we leave.

// Expert insight
“The off-the-shelf PII stack is English-first and quietly silent on Polish, German, or French national identifiers. We published the EU PII model because the Presidio-plus-spaCy pipeline was failing on the languages our customers actually operate in - and the compliance teams were finding out from auditors, not from us.”
Michał Pogoda-Rosikoń
Co-founder @ bards.ai
// Why bards.ai
The model in your deployment is the one we publish.
PII detection is a research problem dressed up as a compliance problem. We did the research first - and the same model in your deployment is the one we publish on Hugging Face.
Published EU PII model
bardsai/eu-pii-anonymization-multilang covers 20+ languages with open weights. The same model in your deployment is what we publish - no licensing surprises, no opaque vendor stack on the safety path.
10+ peer-reviewed NLP publications
CLARIN-PL spinoff. We publish in NLP venues and ship the same models to production - the research and the product are the same artifact.
We've done this exact build before
The engineers on your engagement trained and published the EU PII model - the entity taxonomy, the 20+ language coverage, and the threshold tuning are work they've already done once.
// FAQ
Common questions about PII redaction
On our public benchmark, the multilingual model lands in the 0.92-0.97 F1 range for high-resource entities (PERSON, ORG, LOC, EMAIL) across PL, DE, FR, ES, IT, EN. National identifiers and structured tokens (IBAN, PESEL, IP) hit 0.99+ because they're regex-validatable. We always re-measure on your data before go-live - vendor benchmarks aren't a substitute for your distribution.
On a single A10 or T4, redaction adds 5-15ms per request for typical chat-length inputs and runs in parallel with first-token streaming. For long documents we batch. A distilled variant drops latency by ~3x at a measurable but small recall cost when the budget is tighter.
On detection, each entity is replaced with a stable placeholder ([PERSON_1], [NAT_ID_1]) and the original is stored in a vault keyed by request and tenant. The LLM operates on placeholders. On the response path we rehydrate. The vault lives on your infrastructure - we never see plaintext PII.
It addresses data minimization and pseudonymization (GDPR Art. 5, Art. 25, Art. 32). It does not replace a DPA with your LLM vendor, your Record of Processing, or your DPIA. We help wire those together - but a tool is not a compliance program.
// Related services
Adjacent problems we solve
- Learn more
Trust, PII & Safety
LLM Guardrails & Safety
We measure where Llama Guard drops on your fine-tune, train custom classifier heads that answer in under 10ms, and red-team both chat and agent surfaces.
- Learn more
Trust, PII & Safety
On-Prem & Air-Gapped LLM Deployment
Signed install bundles, an offline model registry, and FIPS-validated crypto - deployment finishes the same day the network is sealed.
- Learn more
Trust, PII & Safety
EU AI Act & GDPR Compliance
Risk classification, technical documentation, and post-market monitoring produced from your CI/CD - in place before the August 2026 deadline.
// Let's ship it
A redaction plan your DPO can sign.
Which languages do you operate in, which entities worry your DPO, and where does the LLM call actually happen? We'll come back with an integration plan and an accuracy estimate on your distribution - usually within a business day.
- Engagements from
- $40K
- Typical range
- $40K-$90K
- Duration
- 4-8 weeks
Fixed-fee proposal after the first scoping call. Scope drivers: language coverage, custom-entity work, integration topology (proxy / SDK / sidecar).
Michał Pogoda-Rosikoń
Co-founder @ bards.ai