01 · GDPR-bound preprocessing was a hand-rolled job at every team
The Challenge
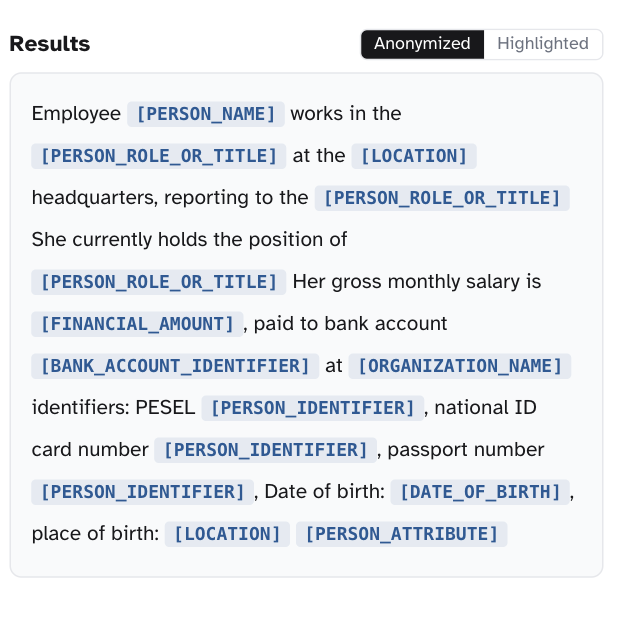
Every team we talked to was solving the same problem from scratch. Before any LLM training, fine-tuning, or analytics could touch user-generated text, the data had to be scrubbed of PII to satisfy GDPR - and that scrubbing was a bespoke pipeline at every team. Regex stacks for emails and phone numbers, off-the-shelf NER for names, custom rules for national IDs that the open-source models didn't know about, and a separate pipeline per language because the labels didn't transfer. Hours of preprocessing work per dataset, brittle in production, and coverage that stopped at whichever languages the team had labelers for.
GDPR scope is broad and language-specific. Names, addresses, phone formats, national IDs, and tax numbers are all country-specific entity types: a model that knows what a German Steuernummer looks like has no idea what a Polish PESEL is, what a Spanish DNI looks like, or how French SIREN numbers are formatted. Coverage across all 24 official EU languages was the whole job - and existing open-source NER tooling stopped short of that.
Recall is the metric that matters under GDPR. A false negative - a PII span the model missed - is a privacy violation that compounds downstream the moment the redacted text leaves the perimeter. A false positive - over-redacting a non-PII span - is recoverable. We needed a model tuned for the asymmetry: recall-first, with a tagging schema mapped to GDPR Article 4(1) categories, packaged so a downstream team could swap in one library call instead of rebuilding the pipeline.