// Research / Custom Fine-tuning
Synthetic data that survives eval.
Teacher distillation from Llama-405B, Qwen-72B, or DeepSeek-V3. Self-instruct, evol-instruct, persona-based generation. Then the part that matters: MinHash deduplication, reward-model filtering, n-gram and embedding contamination checks against your evals. Most synthetic data is mediocre - the pipeline that throws 80% of it away is the deliverable.
// What we see
Synthetic data is mostly a filtering problem, not a generation problem.
01
Teams generate 1M and train on all of it
Raw synthetic output is mostly noise - teacher hallucinations, repetitive prompts, format breaks, off-task responses. Train on all of it and the model regresses on the eval. The kept fraction after filtering - usually 10–25% of raw - is what trains the model. The throw-away ratio is the engagement.
02
Single-teacher monoculture
Distill only from GPT-5 or only from Claude and the student inherits that single teacher's quirks - refusal patterns, hallucination shapes, style tics, factual blindspots. Multi-teacher ensembling and persona-based generation widen the prompt and response distribution so the student doesn't just imitate one model.
03
Contamination silently inflates eval scores
Synthetic prompts overlap eval sets more often than people expect - teachers regurgitate benchmark questions verbatim. Without n-gram and embedding-space contamination checks, your benchmark numbers are lies. We've seen 5–20% leakage rates on uncurated synthetic mixes against MMLU and HumanEval.
// Case Study
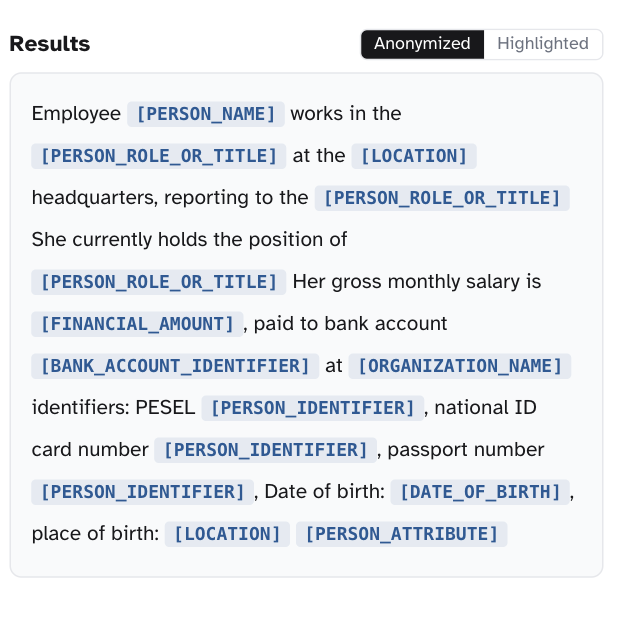
GDPR-compliant PII redaction - 24 EU languages, drop-in
Every GDPR-bound team we worked with was hand-rolling their own preprocessing - regex stacks, per-language NER, hours of pipeline work per dataset, and coverage that stopped at the languages they had labelers for. We shipped `bardsai/eu-pii-anonimization-multilang` as the drop-in library that replaces all of it: one import covers 24 EU languages with a GDPR-aware tagging schema, recall-tuned because false negatives leak. 0.890 F2 on the Gretel benchmark; hours of pipeline work collapse to seconds per dataset.
0.890
F2 on Gretel PII benchmark
24
EU languages with one model
Hours → s
preprocessing per dataset
// What we do
Three layers, from generation to provenance.
Generate broadly, filter aggressively, document everything. The deliverable is a reproducible pipeline you can re-run as the task evolves - not a one-off dataset handed back as a tarball.
Generation - distillation, self-instruct, evol-instruct
Teacher distillation from open-weight frontier models (Llama-3.1-405B, Qwen-2.5-72B, DeepSeek-V3) for license clarity, or from closed models when ToS permits and quality justifies. Self-Instruct for breadth, Evol-Instruct (WizardLM) for difficulty curriculum, persona-based conditioning for voice diversity. Multi-teacher ensembling to avoid single-source monoculture.
- Teacher distillation: Llama-405B, Qwen-72B, DeepSeek-V3, Mixtral-8x22B
- Self-Instruct + Evol-Instruct depth/breadth mutations for difficulty curriculum
- Persona-conditioned generation for diverse voice and style coverage
- Multi-teacher ensembling to dilute single-model quirks
Filtering - reward scoring, dedup, format gates
Reward-model scoring with calibrated quality thresholds. MinHash and SimHash deduplication on prompts and responses (Jaccard threshold tuned per dataset). LLM-as-judge for hard-to-rule-check quality dimensions, calibrated against a small human-graded sample. The pipeline that throws 75–90% of raw output away is the part that matters.
- Reward-model scoring with quality thresholds calibrated against held-out humans
- MinHash / SimHash dedup on prompts and responses (typical: Jaccard < 0.8)
- Length, format, language, and structural gates with explicit removal logging
- LLM-as-judge for subjective quality with bias correction (position swap, length norm)
Contamination + license-aware provenance
N-gram overlap (typically 13-gram) and embedding-space proximity checks against every eval set you care about. Documented removal rates per benchmark. Held-out fresh eval splits the synthesis pipeline never sees, so leakage shows up in the gap. Per-record license provenance so an audit doesn't surprise you.
- 13-gram and substring overlap checks vs MMLU, HumanEval, GSM8K, MATH, your custom evals
- Embedding-space proximity for paraphrase contamination (cosine threshold tuned)
- Per-eval-set decontamination with documented removal counts
- Teacher-license tracking (Llama, Qwen, Mistral CLAs) - audit-ready provenance
// Method fit
Synthetic data fits when labels don't exist or won't scale.
skip it if
You have plentiful, high-quality real labels
If your team or vendor can produce 50K+ well-labeled examples in your domain at acceptable cost, real data will outperform synthetic on the long tail of edge cases. Use synthetic to widen coverage if useful, but it isn't the main lift.
License terms forbid teacher-derived training
OpenAI, Anthropic, and Google ToS historically restrict using their outputs to train competing models. If your engagement is closed-model-locked and the closed model is the only viable teacher, synthetic data can be a legal minefield. Open-weight teachers (Llama, Qwen, Mistral, DeepSeek) sidestep this - and we default to them for the same reason.
Your task is high-stakes safety-critical
Medical, legal, financial advice - domains where teacher hallucinations could land you in a deposition. Synthetic data still has a role for breadth, but the long tail of edge cases needs human-labeled data and the final preference layer needs human judgment.
You don't have a base model to train
Synthesizing data without a downstream training plan is just generating tokens. We do both halves of the engagement; this one is the data layer.
Supervised Fine Tuning (SFT)
use it if
You want to train a smaller specialist (7B-13B) on a task where a frontier model already does it well - distill the capability down at 1/100th the inference cost.
You have a narrow task with no labeled data and labeling would take quarters. Self-instruct + evol-instruct + filter pipelines can bootstrap a 50K-example training set in days.
You want a reproducible synthesis pipeline as a deliverable, so your team can re-generate and re-filter as the task drifts - not a one-off dataset that goes stale.
// How we work
Seed broadly. Filter ruthlessly. Document everything.
Generate more than you'll keep. Filter to the fraction that survives quality and contamination checks. Track provenance per record so license audits are a non-event.
01
Seed prompt design + teacher selection
Seed prompts mined from real user logs, support tickets, or domain experts. Teacher choice driven by license clarity (open-weight first) and quality on a small pilot. Mixture strategy decided up front: pure synthetic vs. 80/20 synthetic-real, depending on the task and the real data we already have.
02
Generate, filter, contamination-check
Self-Instruct + Evol-Instruct + persona conditioning to widen the distribution. Reward-model scoring with quality thresholds. MinHash dedup at typical Jaccard < 0.8. N-gram and embedding contamination checks against every relevant eval set, with documented removal rates. Held-out fresh eval splits never seen by the synthesis loop.
03
Pilot SFT + handoff
Small pilot SFT (10K-subset) to read the loss curve and check eval lift before committing to the full training run. Mixture-ratio sweep where it matters. Hand off the pipeline as code in your repo: seed prompts, teacher configs, filtering thresholds, contamination scripts, provenance manifest, W&B / MLflow runs. Re-runnable as the task evolves.

// Expert insight
“Teams generate a million synthetic examples and train on all of them. We generate ten million, throw eight million away, and train on the remaining two - and it almost always wins. Synthetic data is a filtering problem, not a generation problem.”
Karol Gawron
Head of R&D @ bards.ai
// Why bards.ai
We've trained models from scratch on synthetic data.
Our open-source Polish-language models on Hugging Face - 80K+ monthly downloads - were trained partly on synthetic data we built and curated. We know what survives contact with reality.
16+ open-source models on Hugging Face
Including models trained on substantial synthetic-data components. We've shipped, served, and learned from each one.
Filtering infrastructure that scales
MinHash on tens of millions of documents, embedding-based dedup, reward-model scoring at scale. The throw-away ratio is the deliverable.
10+ peer-reviewed publications
CLARIN-PL spinoff. We've published on data quality, instruction tuning, and Polish NLP - synthetic data sits at the intersection.
Contamination paranoia, by default
13-gram + embedding overlap checks against every eval set. Held-out fresh splits. Documented removal rates. Your benchmark numbers are real, not inflated by leakage.
License-aware provenance
Per-record license tracking, teacher ToS verified before generation. You won't be surprised by an audit because we documented every record's source.
Mixture studies, not folklore
Pure synthetic vs 80/20 vs 50/50 vs curriculum mixing - we run the ablations to find your sweet spot instead of copying a recipe from a paper.
// FAQ
Common questions about synthetic data pipelines
For a focused task on a strong base model, 10K–50K well-filtered examples is often the right zone. Past 100K you're paying for marginal gains unless the task is broad. The kept fraction matters more than raw generation volume - generating 1M and keeping 50K after filtering routinely beats generating 100K and keeping 80K.
Yes - it's a real risk and we treat it explicitly. Distillation transfers both the teacher's strengths and its quirks (hallucination patterns, refusal behaviors, factual errors). We use multi-teacher ensembling, reward-model filtering, and red-team prompts to catch the worst inheritances. For domain-critical tasks we mix in real data to anchor the student against teacher drift.
13-gram overlap between generated prompts/responses and the eval sets we care about (MMLU, HumanEval, GSM8K, MATH, your custom evals), plus embedding-space proximity for paraphrase contamination. Anything that flags gets removed and we document removal rates per benchmark. We also keep held-out 'fresh' eval splits the synthesis pipeline never sees, so leakage shows up in the gap.
Depends on the source. OpenAI, Anthropic, and Google ToS historically restrict using their outputs to train competing models - that's a legal call your counsel needs to make. Open-weight teachers (Llama, Qwen, Mistral, DeepSeek) come with permissive licenses for downstream training. We document provenance for every record so you can answer license audits without drama, and we default to open-weight teachers unless there's a specific reason not to.
For domains where the teacher model is weak or wrong (specialized medical, legal, niche technical), for high-stakes safety-critical evaluations, and for the final preference layer where human judgment is the ground truth. Synthetic data is excellent for breadth and coverage; human labels are still better for the long tail of edge cases and for calibration of reward models.
Reward-model score distributions, length and format statistics, diversity metrics (n-gram entropy, embedding clustering), and small pilot SFT runs on subsets to read the loss curve. We don't train on a million examples without first validating the recipe on 10K and seeing that the pilot model improves on a held-out eval. The pilot saves the engagement when the recipe is wrong.
A pipeline, ideally. Reproducible code, dataset versioning, hash-tracked configs, provenance manifest, W&B / MLflow runs. Your team can re-generate and re-filter as the task evolves - and the synthesis pipeline is usually where most of the IP lives. A static dataset goes stale; a pipeline doesn't.
// Related services
Adjacent problems we solve
- Learn more
Custom Fine-tuning
Supervised Fine Tuning (SFT)
Reproducible fine-tuning with correct chat templates and eval gates - a QLoRA 7B on 50K examples lands in 12-24h and $30-60 of compute.
- Learn more
Custom Fine-tuning
Preference Optimization (DPO / KTO / GRPO)
DPO, KTO, or GRPO chosen by your data shape - for the quality bar SFT alone can't reach.
- Learn more
Custom Fine-tuning
Reinforcement Learning for Agents
PPO with self-play leagues on JAX - thousands of parallel environments per GPU for games and multi-agent decision problems.
// Let's generate it
Bootstrap the dataset, with the filtering that makes it work.
A synthesis recipe, a teacher recommendation, and a number - that's what comes back, usually within a business day. All we need up front: the task, the base model, and the data you do (or don't) have.
Karol Gawron
Head of R&D @ bards.ai